
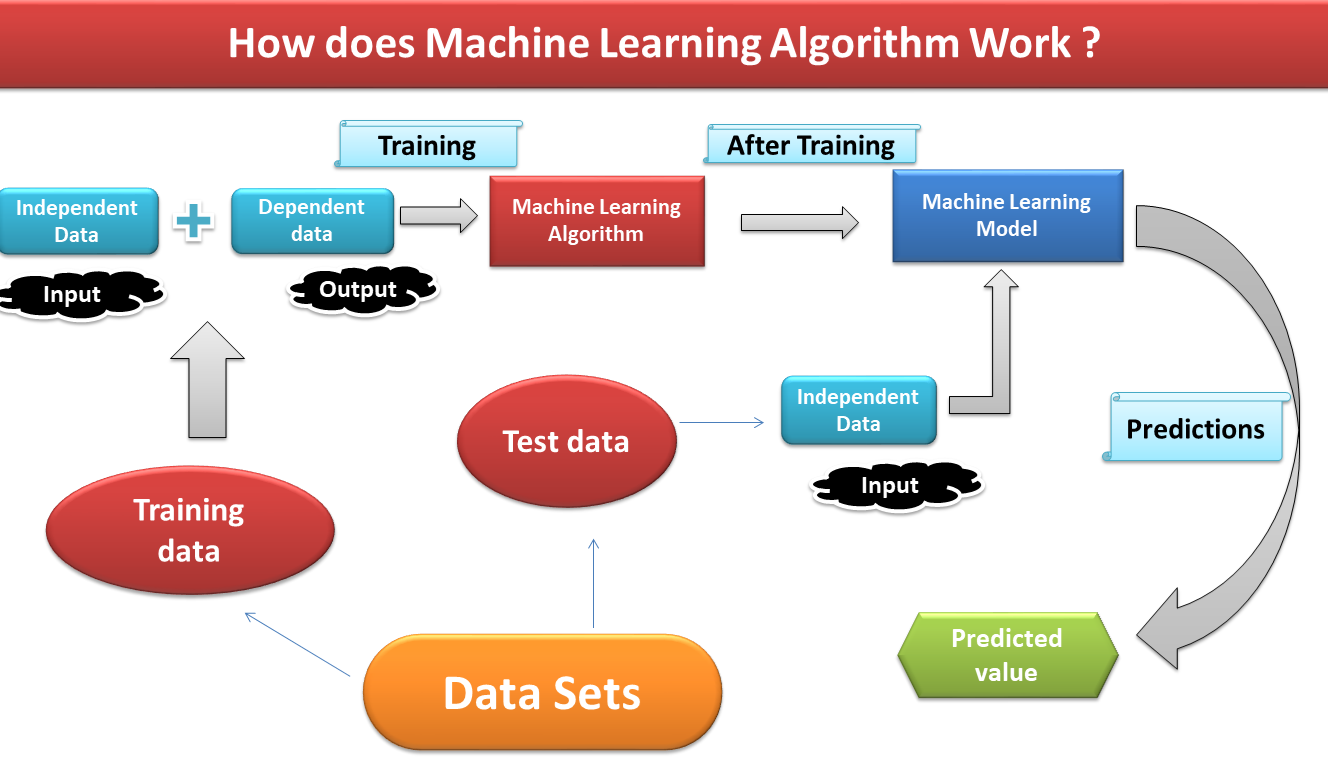
Machine learning algorithm is a computer program that has the ability to learn from data , store its learning and predict if new data comes in. Now think how a newborn baby learns to identify anything. We teach them to see if there is an apple or a ball. The babies see those pictures of apples or balls. Maybe from the very first time they could not correctly identify the difference between an apple and a ball. They sometimes call a ball to an apple and call an apple to a ball. But after seeing many such examples they can identify. When we ask them to tell me what is this? Now the babies can identify correctly .They can speak an apple to an apple or a ball to a ball. The same techniques of teaching also apply while training the Machine learning Algorithm.
We need to feed data(training data) into the ML algorithm, the data must have enough information to the model. Once the model gets trained, we can test it to check its accuracy and performance by feeding the new kind of examples(test data). Once we are satisfied by the results we can use it for deployment. But if we are not satisfied, we can take a different sample of training data, change its feature(column) called feature selection, we can do feature extraction then retrain the model again until we are not satisfied by the test results.
Now understand the important Keywords :
- Dataset
- Training data
- Test data
- Independent variable
- Dependent variable
- Input data
- Output data
- Machine learning algorithm
- Machine learning Model
Data set : Data which is under your observation. This set of data is your point of analysis, deployment cleaning and model Training.
Training Data : It is a part of your Data Set. This portion of data is taken for Model training.
Test Data : It is also a part of the Data set. It is taken for testing your Model accuracy and error. In general we take a 70:30 ratio for train and test splits. That mens 70 percent Training data and 30 percent Test data but It’s up to you.
Independent Variable : This is the input variables or features or factors in your dataset. If your problem statement refers to a supervised problem. Then you treat one portion of data as independent and the other portion as dependent variable.
Dependent variable: This is the output data. Sometimes also called a class or label of each row of your data. The Dependent variable can be numerical or categorical in nature.
For example : sales price prediction, quantity of sales, House price prediction, weather prediction such as Temperature, Moisture, Air velocity Prediction. These kinds of problems have dependent variables of numerical nature because sales price, quantity, Temperature or air velocity is nothing but a number.
Loan prediction, Churn Reduction, Email spam filtering are the kind of problems which have dependent variables of categorical nature. Because it has some classes like Yes or NO, Spam or Non Spam, etc.
Input data : Input data is used as an information for feeding into ML algorithms for training models. The Input data must be cleaned enough for the model’s good performance.
Output Data : It is a target or dependent variable which depends on the input data or independent variables.
Machine learning algorithm : A set of instructions or algorithm which has capability to build models based on training data. The same set of instructions (piece of code) can generate different kinds of Models based on different samples of training data. Each model will predict differently because they got trained on different sets of data.
Now understand with a simple Analogy :
Imagine there are 2 students who are preparing for competitive exams. Each student has a different way of learning and practicing the problems. the 1st student studies 10 hours a day , the 2nd does 12 hours. The 1st one does 1 hour of physical exercise and yoga (brain exercise) but the 2nd one does not. The 1st one sleeps well and makes distance from social media but the 2nd one is fond of social media and doesn’t sleep well.
Now think and compare these two students’ strategies. Is the kind of learning or the information received by their brain equal ? Of Course Not. They will perform differently in the exams.
Similarly if the sample of data is different in each training , the model will generate different results each time and predict the output differently.
Now You can compare your Machine learning algorithm with this strategy of preparations. ML algorithms are the same piece of code always just like the syllabus of the exams every student follows. The ML Models are like students who learn from books or other resources (data). The predicted value by the Model is just like the exam’s result. The result cannot be the same for every student, so different Models predict differently. I hope you have the fundamental understanding of Machine learning Algorithms.
Machine learning Model : it is a product of Machine learning Algorithm. For example You write some piece of code using scikit learn library. In that piece of code you have to feed input data for training. After training you can save your Model as an object file.
For example (In python)
- Model= LinearRegression().fit(X_train, Y_train)
Here, X : input data, y : output data
Now you can predict this way :
- Y_pred= Model.predict(np.array(X_test)
Result : Y_pred is my predicted value
This array is input data, once you insert and run the code it will return an output which is nothing but a predicted value.